

Stage Macro configurations¶
The stage macro provides a variety of configurations to allow users to generate new columns using metadata about columns which exist in the source data.
These new columns can include but are not limited to:
Note
This section documents some specific use cases for certain stage configurations. If you feel any are missing, please get in touch on GitHub!
Video
Available configurations¶
Each of the above are described in more detail below; use the links above for convenience.
Column definition scoping¶
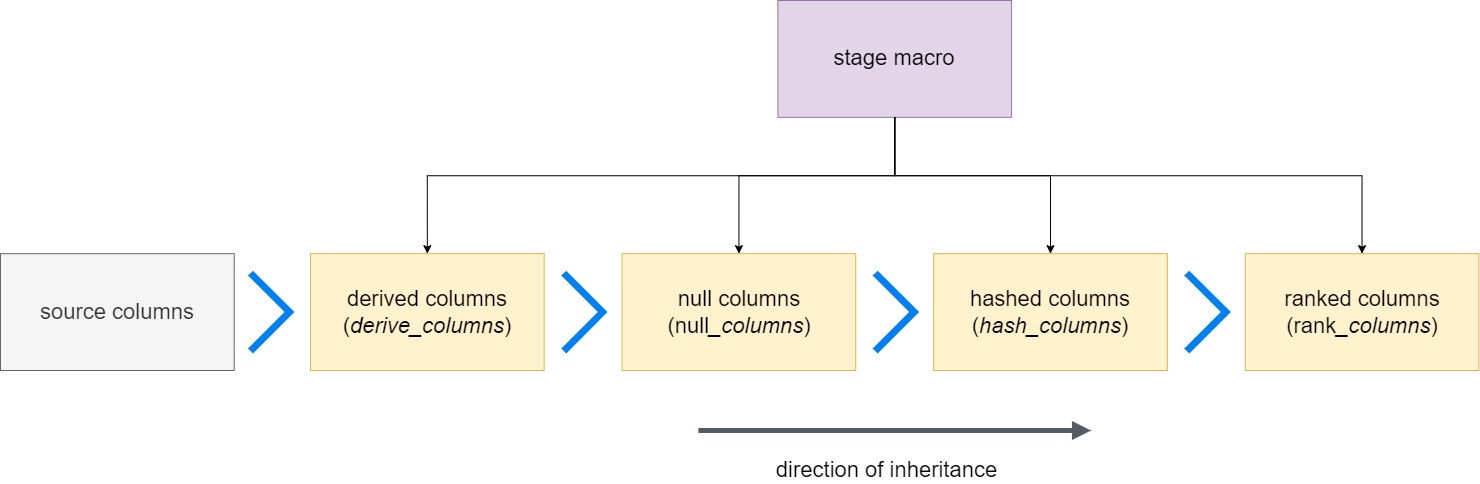
Stage configuration can inherit column definitions from each-other in the order of their definition in the stage macro internal code. The diagram above describes this hierarchy and inheritance. In english, this is as follows:
- Source columns are available to all configurations if
include_source_columnsis set to true, which is the default. - Derived columns have access to all source columns.
- Null columns have access to all derived columns and source columns.
- Hashed columns have access to all derived columns, source columns and null columns
- Ranked columns have access to all source, null, derived, and hashed columns
The above rules open up a number of possibilities:
- Hashed column configurations may refer to columns which have been newly created in the derived column configuration.
- Derived columns are generated in addition to the source column in its derived form, so you can retain the original value for audit purposes.
Note
An exception to #2 arises when overriding source columns
Scoping example using derived and hashed column configurations¶
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Here, we create a new derived column called CUSTOMER_DOB_UK which formats the CUSTOMER_DOB column
(contained in our source) to use the UK date format, using a function. We then use the new CUSTOMER_DOB_UK as a
component of the HASHDIFF column in our hashed_columns configuration.
Derived columns¶
The derived columns configuration in the stage macro allows users to seamlessly create new columns based on the values of columns which exist in the source model for the stage model.
This section describes some specific use cases for the derived columns configuration, with examples.
Tip
You should of course be careful to avoid creating soft rules or business rules in staging. Derived columns are intended for creating minimal hard rules.
Basic Usage¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Note
Overriding source column names¶
It is possible to re-use column names present in the source, for derived and hashed columns. This is useful if you wish to replace the value of a source column with a new value. For example, if you wish to cast a value:
1 2 3 | |
The above snippet, which includes a derived_columns configuration, will re-format the date in the CUSTOMER_DOB
column, and alias it to CUSTOMER_DOB, effectively replacing the value present in that column in this staging layer.
There should not be a frequent need for this functionality, and it is advisable to keep the old column value around for audit purposes, however this could be useful in specific situations.
Defining new columns with functions¶
1 2 3 4 5 | |
1 2 3 4 5 | |
In the above example we can see the use of a function to convert the date format of the CUSTOMER_DOB to create a new
column CUSTOMER_DOB_UK. Functions are incredibly useful for calculating values for new columns in derived column
configurations.
In the highlighted derived column configuration in the snippet above, the generated SQL would be the following:
1 | |
Note
Please ensure that your function has valid SQL syntax on your platform, for use in this context.
Defining Constants¶
1 2 3 4 5 | |
1 2 3 4 5 | |
In the above example we define a constant value for our new SOURCE column. We do this by prefixing our string with an
exclamation mark: !. This is syntactic sugar provided by AutomateDV to avoid having to escape quotes and other
characters.
As an example, in the highlighted derived column configuration in the snippet above, the generated SQL would look like the following:
1 2 3 4 | |
1 2 3 4 | |
And the data would look like:
| CUSTOMER_DOB_UK | RECORD_SOURCE | EFFECTIVE_FROM |
|---|---|---|
| 09-06-1994 | RAW_CUSTOMER | 01-01-2021 |
| . | RAW_CUSTOMER | . |
| . | RAW_CUSTOMER | . |
| 02-01-1986 | RAW_CUSTOMER | 07-03-2021 |
Defining Composite columns¶
1 2 3 4 5 6 7 8 | |
You can create new columns, given a list of columns to extract values from, using derived columns.
Given the following values for the columns in the above example:
CUSTOMER_ID= 0011CUSTOMER_NAME= Alex
The new column, CUSTOMER_NK, would contain 0011||Alex||DEV.
The values get joined in the order provided, using a double pipe ||.
The values provided in the list can use any of the previously described syntax (including functions and constants) to generate new values, as the concatenation happens in pure SQL, as follows:
1 2 | |
Escaping column names that are not SQL compliant¶
To enable the escaping functionality, a mapping of the source column name and an escape flag must be provided. Alternatively, for computed derived columns, escape characters can be explicitly coded within the function itself.
Check out the following metadata examples:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Generated SQL:
1 2 3 4 5 6 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Generated SQL:
1 2 3 4 5 6 | |
Note
Please ensure that your functions have valid SQL syntax on your platform, for use in this context.
Null Columns¶
This stage configuration provides the user with the means to define required and optional Null keys according to business needs. This is a standard Data Vault 2.0 approach for ensuring that records are loaded into Hubs and Links even if they are null, allowing the business to enforce meaning for these keys.
Enabling NULL key value replacement¶
Where key columns might have a null value in the source data and there is a requirement to import the associated records, the null key can be replaced by a default value and the original null value stored in an additional column. The key might be required, for instance where it is the basis for a hashed primary key, or it might be optional.
- The default replacement value for a required key is -1
- The default replacement value for an optional key is -2
The replacement process is enabled as follows:
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 | |
Hashed columns¶
The hashed columns configuration in the stage macro provides functionality to easily and reliably generated hash keys and hashdiffs for various AutomateDV (and Data Vault 2.0) tables and structures.
This section describes some specific use cases for the hashed columns configuration, with examples.
Read
Basic Usage¶
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Note
Exclude Flag (hashed_columns)¶
A flag can be provided for hashdiff columns which will invert the selection of columns provided in the list of columns.
This is extremely useful when a hashdiff composed of many columns needs to be generated, and you do not wish to individually provide all the columns.
The snippets below demonstrate the use of an exclude_columns flag. This will inform AutomateDV to exclude the columns
listed under the columns key, instead of using them to create the hashdiff.
Hash every column without listing them all
You may omit the columns key to hash every column. See the Columns key not provided example below.
Examples¶
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Warning
Care should be taken if using this feature on data sources where the columns may change. If you expect columns in the data source to change for any reason, it will become hard to predict what columns are used to generate the hashdiff. If your component columns change, then your hashdiff output will also change, and it will cause unpredictable results.
Ranked Columns¶
Generates SQL to create columns using the RANK() or DENSE_RANK() window function. This is predominantly for use with
custom AutomateDV materialisations.
Defining and configuring Ranked columns¶
This stage configuration is a helper for
the vault_insert_by_rank materialisation.
The ranked_columns configuration allows you to define ranked columns to generate, as follows:
1 2 3 4 5 6 7 8 | |
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 | |
Dense rank¶
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 | |
Order by direction¶
1 2 3 4 5 6 7 8 9 | |
1 2 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 | |